In der letzten Zeit habe ich mir viele Gedanken über Softwarearchitektur Entscheidungen und nachhaltige Programmierung gemacht. Genau genommen tat ich das die letzten Jahre. Dabei habe ich viele Entscheidungen neu bewertet, überdacht und ständig dazu gelernt.
Auch jetzt ist der Lernprozess lange nicht abgeschlossen. Neue Projekte und neue Menschen bringen stets neue Impulse und Möglichkeiten. Aber ich möchte die Gelegenheit ergreifen zu versuchen zu beschreiben was für mich “ein Softwareprojekt” eigentlich ist.
Und das ist gar nicht so einfach, denn ich möchte es für dich als Entwickler so interessant wie möglich, oder für dich als Nicht-Entwickler so verständlich wie möglich darstellen. Daher habe ich mich dazu entschieden dies an einem Konkreten Beispiel zu machen.
Das Beispiel
Lass uns mal träumen: angenommen wir haben ein Unternehmen im Bereich Autoversicherungen – ein Startup, oder ein bereits etabliertes Unternehmen. Da wir mit dem Zahn der Zeit gehen haben wir beschlossen, dass wir unser Unternehmen datengetrieben aufbauen- bzw. umstrukturieren wollen.
Hier auch direkt der erste Einschub: datengetrieben – was bedeutet das eigentlich? Eine klare Definition gibt es glaube ich gar nicht. Wir als Unternehmer wollen so gewinnbringend wie möglich handeln. Das bedeutet eine realistische Risikoeinschätzung unserer Kunden. Gleichzeitig wollen wir so viele Kunden wie möglich, das bedeutet wir müssen ein ansprechenendes Produkt haben. Eine vernünftige Risikoeinschätzung bekommen wir mit möglichst genauen und aktuellen Daten unserer Kunden. Hierzu zählen natürlich Stammdaten wie Adresse, Alter, Wohnort, Berufsgruppe. Gleichzeitig zählen hier auch Verhaltensdaten: halten sich die Kunden oder Kundinnen an die Geschwindigkeitsbegrenzungen, fahren sie täglich oder nur gelegentlich, wie lang sind die strecken, sind auf dem täglichen Arbeitsweg überdurchschnittlich viele Unfälle, und so weiter. Es liegen also weitgehend gleichbleibende Daten in Form von Stammdaten und veränderliche bzw. stetig hinzukommende Daten vor. Diese zu erfassen und zu verwerten gleicht einem Kunststück. Wir sprechen hier nicht von einer momentanen Erfassung von Daten, sondern um einer historischen Erfassung inklusive gegebenenfalls einer Echtzeitauswertung der momentanen Daten.
Aber Butter bei die Fische: wie kriegen wir diese wirklich hilfreichen Daten eigentlich?
Da wir wie vorhin erwähnt im Zahn der Zeit gehen natürlich mit einer App. Die Kundinnen und Kunden installieren sich die App auf ihrem Mobiltelefon und bei jeder Fahrt wird sie eingestellt. Die App überträgt uns dann in Echtzeit die aktuellen GPS Daten und weitere Sensordaten vom Handy. So kriegen wir alle Informationen die wir benötigen um das Fahrverhalten auszuwerten und einen Risikoscore zu bestimmen.
Aber was bedeutet eigentlich Echtzeit?
Das ist ein gerne beiläufig verwendeter Begriff. Theoretisch wollen wir rückwirkend zu jedem beliebigen Zeitpunkt bestimmen können wann sich unsere Kunden oder Kundinnen befinden. Technisch umgesetzt kannst du dir vorstellen, dass wir jeden GPS Punkt inklusive Uhrzeit in eine fortlaufende Datei schreiben. Als Echtzeit bezeichnen wir anschließend das kleinst mögliche Zeitintervall in dem GPS Daten in in diese Datei gelegt werden mit dem wir zufrieden sind. Das kann jede Nanosekunde, Millisekunde, Sekunde, Minute oder gar Stunde sein – wobei der Echtzeitbegriff insbesondere in großen Zeitintervallen dann gerne mal in Frage gestellt werden darf.
Nun stellt sich natürlich noch eine weitere Frage: Was machen wir mit den gesammelten Daten?
Die Antwort ist eines der sexiesten Antworten die es gibt: Machine Learning. Konkret fällt mir hier ein Kundenclustering und Clusterbezogene Zeitreihenanalyse ein. Aber das sind nur zwei Möglichkeiten von vielen. Fakt ist: Daten sind zum auswerten da. Und genau das muss getan werden.
Nun wo der Rahmen klar ist, wir das Produkt verstanden haben, lass uns doch mal an die Umsetzung gehen.
Homepage
Die habe ich in den Punkten oben nicht erwähnt, darf aber trozdem auf gar keinen Fall vergessen werden. Wie sonst sollen uns Kunden im Netz finden und Kontaktieren? Instagram, Twitter und Co. sind mit Sicherheit interessant und auch relevant, aber an eine Homepage führt kein Weg dran vorbei.
Die Homepage hat erstmal nichts mit dem Produkt selbst zu tun. Sie dient dazu Kunden zu Gewinnen und ggf. um Rückfragen abzuwickeln. Das kann beliebig umgesetzt werden. PHP und WordPress ist wohl die gängigste Variante. Ich persönlich bin aber kein großer Freund von WordPress und tendiere eher zu Python Lösungen – im konkreten Fall vermutlich Python Django.
Die Homepage soll eine Landingpage & Kundenfunnel sowie Nutzerbereich erhalten. Im Nutzerbereich werden bestenfalls Dashboards zum vergangenen Fahrverhalten angezeigt oder Kundensupportfeatures zu verfügung gestellt.
Wenn man hier WordPress nimmt, muss man es schon wirklich wollen. Ich will nicht
Handyapp
Hier liegt das eigentliche Monster. Die Diskussion ob hybrid oder nativ ist schnell beantwortet: man muss für die App aktiv auf die Sensoren der Smartphones zugreifen. Das geht i.d.R. am ehesten mit einer nativen App. Im Worse Case muss man also die selbe App in verschiedenen Programmiersprachen entwickeln.
Viel interessanter als die App ist aber wie die Daten gespeichert werden. Denn wir brauchen diese Daten zur Auswertung in Echtzeit bei uns auf dem Server.
Die erste Überlegung ist hier natürlich das bereitstellen einer einfachen Rest API und Datenbank. Wie im Schaubild exemplarisch abgebildet.
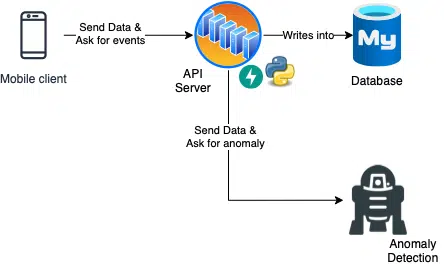
Eine erste Planung: Ein Mobilgerät schickt Daten an einen Server. Diese werden in eine Datenbank geschrieben und ein Echtzeit von einer KI bewertet. Diese macht erstmal nichts mit den Daten.
Bevor das in Stein gemeißelt wird, macht es Sinn hier nochmal kurz durchzuatmen – ist nämlich gar nicht so einfach!
Ein großes Problem ist die snychrone Kommunikation. Vom Handy werden mit einem Post-Request Daten an einen Server geschickt. Bevor das Handy weitermachen kann, muss es allerdings noch auf die Antwort des Servers warten. Die kommt aber erst, sobald der Datensatz erfolgreich in eine Datenbank geschrieben wird und nachdem geschaut wurde ob eine Anomalie vorliegt.
Das ist alles suboptimal. Schöner wäre es, wenn sich die Anomalie Detektion proaktiv meldet und dieser Prozess vom Verschicken der Daten entkoppelt wäre.
Zudem wird ggf. ständig ein GPS Signal gesendet werden müssen (z.B. zum bestimmen der aktuellen Geschwindigkeit und Abgleich mit den Geschwindigkeitsbegrenzungen im Streckenabschnitt), oder das Handy schickt Informationen über G-Kräfte und ihre Richtungen an den Server damit das Bremsverhalten oder Fahrverhalten in Kurven ausgewertet werden kann. Vielleicht kommt auch noch mehr an Daten hinzu. Fakt ist aber: das ist ein sehr großer Datendurchsatz.
Und plötzlich kann man überlegen ob eine normale Rest API überhaupt noch geeignet ist, oder ob man hier nicht eher eine langlebige Verbindung zu einem ständigen Datenaustausch mittels Websockets bereitstellen möchte.
Gleichzeitig handelt es sich hier eher um Daten mit einer klaren Zeitabhängigkeit – in anderen Worten: Zeitreihen. Hier bieten sich Datenbanken wie Prometheus, InfluxDB oder wenn man bei AWS unterwegs ist auch TimescaleDB an.
Ein Bottleneck welches sich hier ergibt ist das hochfrequentierte schreiben in eine Datenbank. Dabei gibt es eigentlich immer Probleme. Eine Überlegung hier ist die entkopplung des Webservers vom Schreibprozess in die Datenbank z.B. mit einer Daten Streaming Lösung wie Apache Kafka in der Mitte.
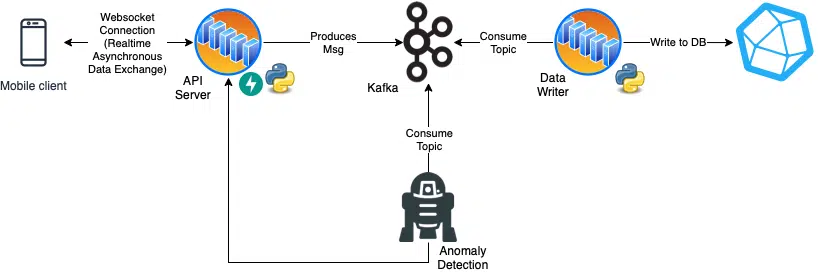
Zweiter Entwurf: Anstelle einer einfachen HTTP Schnittstelle werden Websockets verwendet, ein anderes Webprotokoll, dies ermöglicht einen kontinuierlichen Datenstrom aufrecht zu erhalten. Gleichzeitig wird nicht sofort in eine Datenbank geschrieben, sondern noch ein Tool – in dem Fall Kafka – in die Mitte gehangen. Dadurch werden einzelne Prozesse entkoppelt. Der Gesamtprozess ist wesentlich komplexer und dauert ggf. auch länger, allerdings sind die einzelnen Komponenten schneller und leichter zu skalieren was insbesondere im API Server relevant sein kann.
Und Schwupp – weg von der 0815 Rest API MySQL Struktur, hin zu einer spannenden, komplexen, individualisierbar skalierbarer Lösung zur Abwicklung des selben Problems. Und berechtiger weise kann man sich die Frage stellen, warum man sich freiwillig für eine maximal komplexe Lösung entschieden werden soll – warum sich scheinbar selbst ins Bein schießen?
Ich kann leider nur nüchtern sagen: das zu vergleichen wird ein eigener Blog Beitrag. Ich bin hier hin- und her gerissen. An sonnigen Tagen entscheide ich mich für die erste, an bewölkten Tagen für die zweite Lösung.
Es gibt übrigens auch abseits von Microservices andere Möglichkeiten ein solches Vorhaben Umzusetzen. Konkret fällt mir hier sogar Akka ein. Das ermöglicht eine eventbasierte, verteilte und persistente Datenverarbeitung bleibt dabei aber weitgehend monolithisch (wenn man es nicht auf anderes anlegt). Ich glaube Akka ist für bestimmte Fälle ein sehr interessanter Geheimtipp. Auch das wäre wieder ein eigener Blogbeitrag.
Data Science & Machine Learning
Jetzt wo sich über die Architektur grob gedanken gemacht wurde, wird zum wirklich spannenden Teil über gegangen.
Im wesentlichen werden verschiedene Arten von Data Science gegenüber gestellt:
- implementierung für präventive Maßnahmen z.B. Anomalie Detektion
- implementierung zu Zeitversetzten Analysezwecken
- Unternehmens Abalyse Zwecke
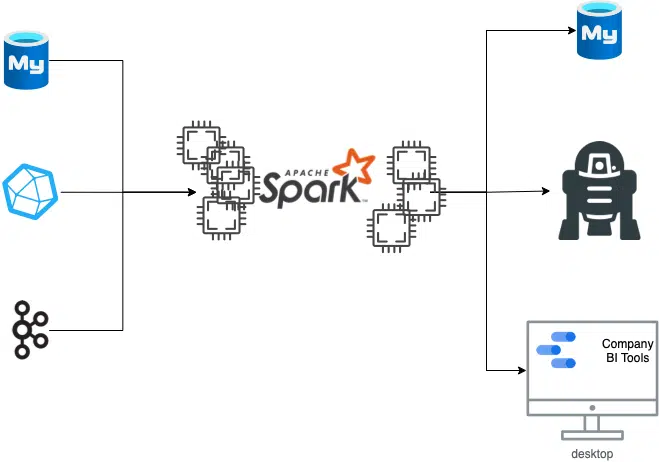
Hier gibt es wieder unzählige Ansätze. In diesem Beispiel wurde sich für einen Ansatz mit Apache Spark entschieden.
Spark hat die wunderbare eigenschaft, dass es Prozesse über verschiedene Maschinen Hinweg verteilen kann. Weiter kann Spark wunderbar verschiedene Datenquellen in sich vereinen und einem DataScientisten die Möglichkeit geben mit verschiedenen Datenquellen auf die gleiche Art zu arbeiten.
Im Konkreten Fall wird Spark sowohl als Pipeline genutzt (direktes schreiben in eine für den Nutzer zugängliche Datenbank um spätere Analysen zum eigenen Fahrverhalten abzurufen), als auch zum Trainieren von Modellen zur Anomalie-Detektion, als auch zum visualisieren von Daten als rein Firmeninterner Anspruch.
Eine echte Allzweckwaffe also.
Wie geht’s hier weiter?
Nun, bisher haben wir uns nur über die Umsetzung unterhalten ohne Konkret umzusetzen. Wobei … das ist nicht ganz wahr. Schau mal hier: FunWithMicroservices
Hier findest du zu genau unserem Projekt eine konkrete Umsetzung im kleinen Stil von mir.
Aber davon ganz abgesehen sind wir an einem Punkt wo wir überlegen müssen: Wie viel, wie gut und wie teuer muss bzw. darf es denn eigentlich werden?
Und hier muss einfach klar sein: So Projekte sind immer ein riesen Tradeoff. Denn zur konkreten Umsetzung gehört auch die entsprechende Pflege, Weiterentwicklung und vor allem auch das sogenannte Monitoring oder testing.
Ich habe schon oft erlebt und gehört dass Kunden einen Prototyp umgesetzt haben sollen. Prototyp bedeutet oftmals eine Testversion an einer Software für einen möglichst kleinen Kreis von Nutzern und Nutzerinnen. Oft wächst der provisorisch kleine Kreis von Nutzern und Nutzerinnen unverhofft schnell. Oder in anderen Worten: der Prototyp wird nicht wie vereinbart nur für Testzwecke genutzt, sondern auch produktiv für den echten Betrieb.
Genau das ist durchaus legitim. Denn oberflächlich steht ein nutzbares Produkt welches genauso arbeitet wie man es erwarten würde.
Was dann aber oft passiert ist, dass sich Feature Entwicklung und Bugfixes in großer Menge vermischen und sich Bugs mit neuen Features häufen, oder dass ständig neue Wehwehchen der Nutzer und Nutzerinnen hinzukommen.
Und um das klar zu machen: Eine Anwendung ist immer mehr als das was man sieht und nutzt. Um eine Anwendung lauffähig zu halten muss man sie als Entwickler oder Entwicklerin beobachtbar machen. Dazu gehört möglichst einfach zu sehen wie die Lastverteilung auf den Servern aussieht, im Falle der Verwendung von Kafka möchten wir unbedingt sehen wie viele Messwerte noch nicht verarbeitet wurden (man spricht vom Consumer Gap. Steigt der Gap heißt das, dass etwas mit unserer Anwendung nicht stimmt). Im Falle unseres API Servers möchten wir ggf. sehen ob unsere Instanzen vernünftig geballanced werden, oder wir wollen generell sehen ob alle unsere Server gerade “gesund” sind, denn am Ende läuft alles auf echter Hardware die zu unter 1% ausfallen kann.
Gleichzeitig wollen wir sichergehen dass Anwendungen so arbeiten wie erwartet indem man z.B. Logs permanent und zentral abspeichert.
Natürlich wollen wir auch möglichst schnell und effizient entwickeln können was oft bedeutet dass der ganze Deploymentprozess automatisiert werden muss.
Gleichzeitig muss auch noch bestenfalls sicher gestellt werden, dass die Features permanent funktionieren – auch nach Änderungen noch. Hierzu werden Tests geschrieben.
Und all das ist nur die Spitze des Eisbergs. Aber all das gehört irgendwie zur Software dazu. Und alles ist mit einem recht indirekten und hypothetischem Nutzen für das Produkt sowie sehr konkreten Aufwand verbunden. Aus diesem Grund muss immer die Frage gestellt werden: Was hiervon brauchen wir eigentlich?
Aber ja – hier liegt nochmal ein riesiger Bereich verborgen über den man natürlich nochmal einen ganz ganz eigenen Blogartikel schreiben kann.
Autor
Janis Gösser ist Software Engineer bei Ailio. Er liebt den Pizza Tag und bringt manchmal Mira – seinen süßen Hund mit ins Büro. Außerdem hat Janis einen Kafka Fetisch.
Sie wollen diese Themen angehen?
Die Ailio GmbH ist ein auf Data-Science und Künstliche Intelligenz spezialisierter Dienstleister aus Bielefeld. Wir beraten in beiden Bereichen und entfesseln das Potential der Daten, die momentan im deutschen Mittelstand brach liegen. Dabei gehen wir kostenoptimierend und risikominimierend vor. Bei Interesse kontaktieren Sie uns gerne direkt!

