Lately, I’ve been thinking a lot about software architecture decisions and sustainable programming. In fact, I’ve been doing that for the last few years. In the process, I reevaluated and reconsidered many decisions and constantly learned.
Even now, the learning process is far from complete. New projects and new people always bring new impulses and opportunities. But I would like to take the opportunity to try to describe what “a software project” actually is for me.
And it’s not that easy, because I want to make it as interesting as possible for you as a developer, or as understandable as possible for you as a non-developer. Therefore I decided to do this with a concrete example.
The example
Let’s dream: suppose we have an auto insurance company – a startup, or an already established company. As we move with the times, we have decided to build and restructure our company in a data-driven way.
Here also directly the first insertion: data-driven – what does that actually mean? I don’t think there is a clear definition at all. As entrepreneurs, we want to act as profitably as possible. This means a realistic risk assessment of our customers. At the same time, we want as many customers as possible, which means we have to have an appealing product. We get a reasonable risk assessment with the most accurate and up-to-date data possible from our customers. This of course includes master data such as address, age, place of residence, occupational group. At the same time, behavioral data also counts here: do customers keep to the speed limits, do they drive daily or only occasionally, how long are the routes, are there an above-average number of accidents on the daily commute, and so on. This means that there is largely constant data in the form of master data and variable data or data that is constantly being added. Capturing and utilizing these is like a feat. We are not talking about a momentary collection of data, but about a historical collection including, if necessary, a real-time evaluation of the momentary data.
But butter on the fish: how do we actually get this really helpful data?
Since we go as mentioned earlier in the tooth of time of course with an app. Customers install the app on their cell phones and it is set for each trip. The app then transmits the current GPS data and other sensor data from the cell phone to us in real time. This gives us all the information we need to evaluate driving behavior and determine a risk score.
But what does real time actually mean?
This is a term that is often used casually. Theoretically, we want to be able to determine retroactively at any point in time when our customers are located. Technically implemented you can imagine that we write every GPS point including time into a continuous file. Then we call real time the smallest possible time interval in which GPS data is put into this file that we are satisfied with. This can be every nanosecond, millisecond, second, minute or even hour – whereby the real-time concept can be questioned, especially in large time intervals.
Now, of course, another question arises: what do we do with the collected data?
The answer is one of the sexiest answers there is: Machine Learning. Specifically, customer clustering and cluster-based time series analysis come to mind. But these are just two possibilities among many. The fact is: data is there to be evaluated. And that is exactly what needs to be done.
Now that the framework is clear, we have understood the product, let’s get down to implementation.
Homepage
I have not mentioned this in the points above, but it must not be forgotten in any case. How else should customers find and contact us on the web? Instagram, Twitter and the like are certainly interesting and relevant, but there is no way around a homepage.
The homepage has nothing to do with the product itself. It is used to win customers and, if necessary, to handle queries. This can be implemented in any way. PHP and WordPress is probably the most common variant. Personally, though, I’m not a big fan of WordPress and tend more towards Python solutions – in this particular case, probably Python Django.
The homepage should get a landing page & customer funnel as well as user area. At best, the user area displays dashboards on past driving behavior or provides customer support features.
If you take WordPress here, you really have to want it. I do not want
Mobile app
This is where the real monster lies. The discussion whether hybrid or native is quickly answered: you have to actively access the sensors of the smartphones for the app. This is usually best done with a native app. In the worst case, you have to develop the same app in different programming languages.
But much more interesting than the app is how the data is stored. Because we need this data for evaluation in real time on our server.
The first consideration here is of course to provide a simple rest API and database. As shown in the diagram as an example.
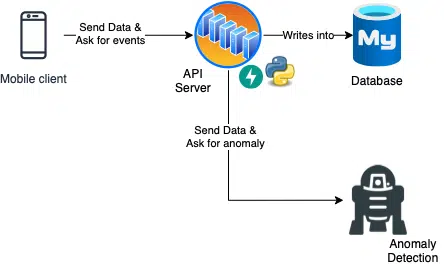
An initial plan: A mobile device sends data to a server. These are written to a database and evaluated in real time by an AI. This does nothing with the data for the time being.
Before this is set in stone, it makes sense to take another breath here – because it’s not that easy!
A major problem is snychronous communication. Data is sent from the cell phone to a server with a post-request. However, before the phone can continue, it must wait for the server’s response. However, this only occurs once the data set has been successfully written to a database and after a check has been made to see whether an anomaly exists.
It’s all suboptimal. It would be nicer if the anomaly detection reported proactively and this process was decoupled from sending the data.
In addition, a GPS signal may have to be sent constantly (e.g. to determine the current speed and compare it with the speed limits in the track section), or the cell phone sends information about G-forces and their directions to the server so that braking behavior or driving behavior in curves can be evaluated. Perhaps more data will be added as well. But the fact is: this is a very large data throughput.
And suddenly you can consider whether a normal Rest API is still suitable at all, or whether you would rather provide a long-lasting connection to a constant data exchange via websockets.
At the same time, these tend to be data with a clear time dependence – in other words, time series. Databases such as Prometheus, InfluxDB or, if you’re on AWS, TimescaleDB are good choices here.
A bottleneck that arises here is the high-frequency writing to a database. Actually, there are always problems. One consideration here is to decouple the web server from the writing process to the database e.g. with a data streaming solution like Apache Kafka in the middle.
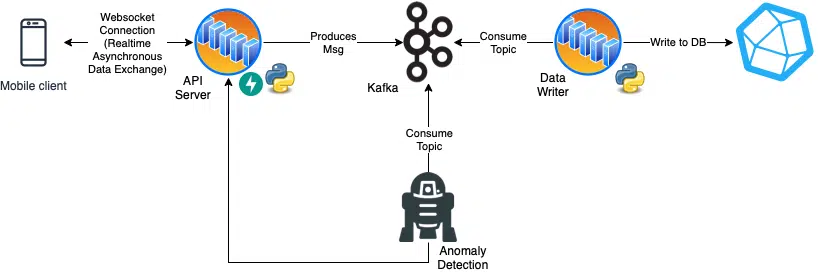
Second design: Instead of a simple HTTP interface, Websockets are used, a different web protocol, this allows to maintain a continuous data stream. At the same time, you don’t write to a database right away, but hang another tool – in this case Kafka – in the middle. This decouples individual processes. The overall process is much more complex and may take longer, but the individual components are faster and easier to scale, which can be particularly relevant in the API server.
And poof – away from the 0815 Rest API MySQL structure, to an exciting, complex, customizable scalable solution to handle the same problem. And justifiably one can ask oneself why one should voluntarily choose a maximally complex solution – why seemingly shoot oneself in the foot?
Unfortunately, I can only say soberly: to compare this will be a separate blog post. I’m torn here. On sunny days I opt for the first solution, on cloudy days for the second.
By the way, there are other ways to implement such a project apart from microservices. Specifically, even Akka comes to mind here. This enables event-based, distributed and persistent data processing, but remains largely monolithic (if you don’t mind otherwise). I think Akka is a very interesting insider tip for certain cases. Again, that would be a blog post of its own.
Data Science & Machine Learning
Now that the architecture has been roughly thought about, we move on to the really exciting part.
Essentially, it contrasts different types of Data Science:
- implementation for preventive measures e.g. anomaly detection
- implementation for time-shifted analysis purposes
- Company Abalysis Purposes
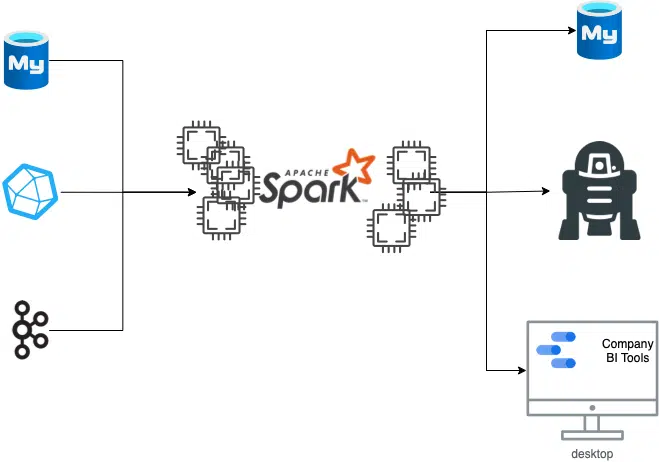
Here again there are countless approaches. In this example, an approach using Apache Spark was chosen.
Spark has the wonderful feature that it can distribute processes across different machines. Further, Spark can beautifully unify different data sources and allow a DataScientist to work with different data sources in the same way.
In the concrete case, Spark is used both as a pipeline (writing directly into a database accessible to the user to retrieve later analyses of one’s own driving behavior), as well as for training models for anomaly detection, and for visualizing data as a purely internal company requirement.
A real all-purpose weapon, then.
What’s the next step here?
Well, so far we have only talked about the implementation without concretely implement. Whereby … that is not entirely true. Look here: FunWithMicroservices
Here you will find a concrete implementation of exactly our project in small style from me.
But quite apart from that, we are at a point where we have to consider: How much, how good and how expensive does it actually have to be?
And here it must be clear: such projects are always a huge tradeoff. This is because concrete implementation also includes the corresponding maintenance, further development and, above all, so-called monitoring or testing.
I have often experienced and heard that customers have implemented a prototype. Prototype often means a test version of a software for a small group of users. Often the provisionally small circle of users grows unexpectedly fast. Or in other words: the prototype is not only used for testing purposes as agreed, but also productively for real operation.
This is exactly what is legitimate. Because on the surface there is a usable product that works exactly as you would expect.
But what often happens then is that feature development and bug fixes get mixed up in large quantities and bugs pile up with new features, or that new aches and pains of users are constantly added.
And to make this clear: An application is always more than what you see and use. To keep an application executable, a developer must make it observable. This includes seeing as easily as possible what the load distribution on the servers looks like, in the case of using Kafka we definitely want to see how many readings have not been processed yet (this is called the consumer gap. If the gap increases, it means that something is wrong with our application). In the case of our API server, we may want to see if our instances are reasonably ballanced, or we may generally want to see if all of our servers are “healthy” right now, because in the end, everything runs on real hardware that can fail at less than 1%.
At the same time we want to make sure that applications work as expected by e.g. storing logs permanently and centrally.
Of course, we also want to be able to develop as quickly and efficiently as possible, which often means that the entire deployment process has to be automated.
At the same time, it must also be ensured at best that the features work permanently – even after changes have been made. Tests are written for this purpose.
And all this is just the tip of the iceberg. But all that is somehow part of the software. And everything is associated with a rather indirect and hypothetical benefit for the product as well as very concrete effort. For this reason, the question must always be asked: What of this do we actually need?
But yes – here lies another huge area hidden about which you can of course write a whole separate blog article.
Author
Janis Gösser is a software engineer at Ailio. He loves pizza day and sometimes brings Mira – his cute dog to the office. Also, Janis has a Kafka fetish.
Do you want to address these issues?
Ailio GmbH is a Bielefeld-based service provider specializing in data science and artificial intelligence. We advise in both areas and unleash the potential of data that is currently lying fallow in German SMEs. In doing so, we take a cost-optimizing and risk-minimizing approach. If you are interested, please contact us directly!



