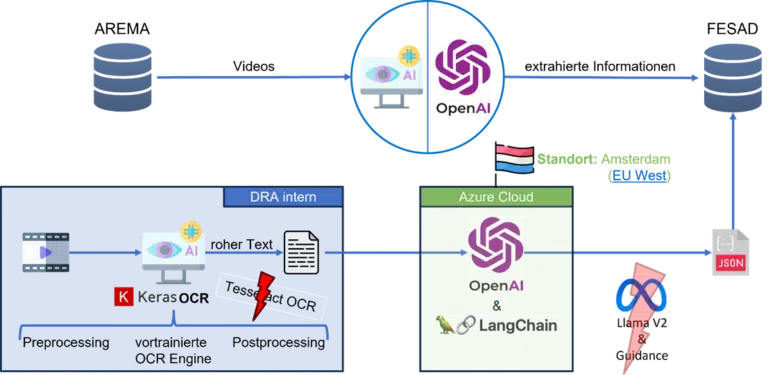
Unser Tooling hat sich konstant weiterentwickelt, um sich an die Anforderungen des Projektes anzupassen. In der finalen Version haben wir mit KerasOCR (Pre- sowie Postprocessing), OpenAI on Azure, LangChain, JSON sowie selbst entwickelten Python Schnittstellen und einer Anbindung an On-Prem Server gearbeitet.